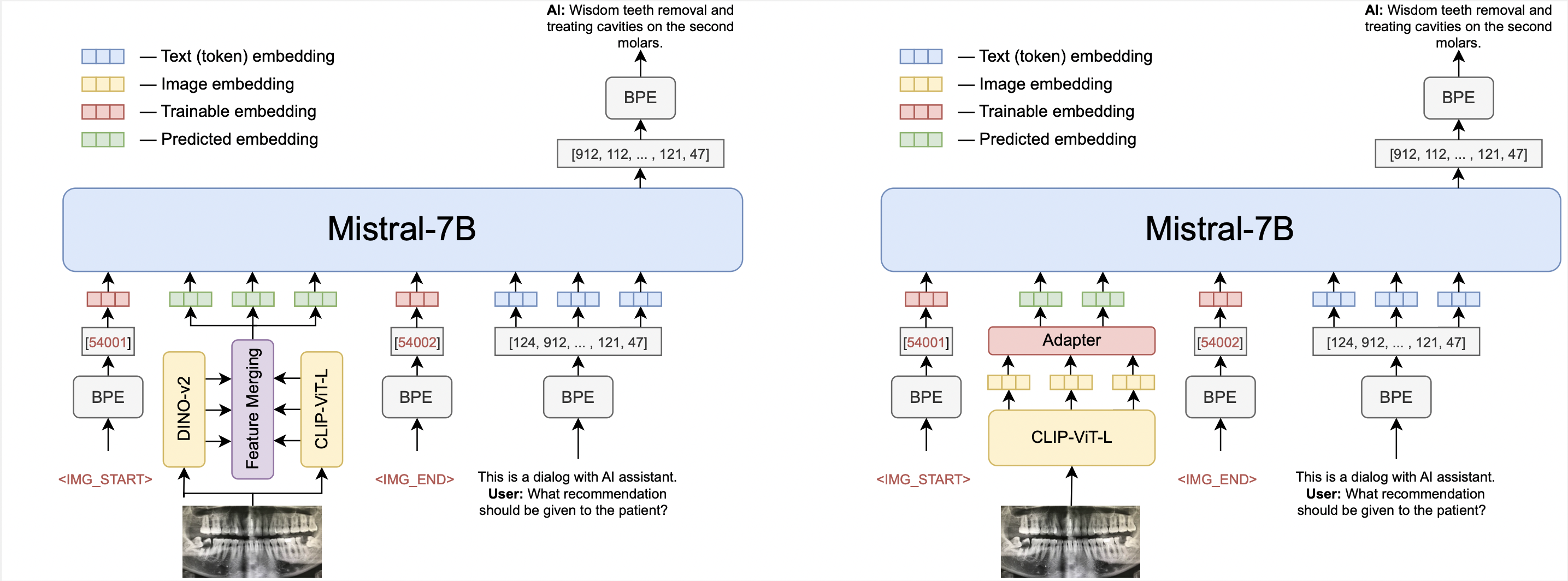
OmniFusion Architecture
OmniFusion Architecture
There are two architecture options for the OmniFusion model. The first option uses one visual encoder (CLIP ViT-L/14), the second uses two encoders (CLIP ViT-L/14 and DINO v2). OmniFusion connects pre-trained visual encoders and large language model, using trainable adapter.
We consider a two-stage instruction-tuning procedure:
- Stage 1: Pre-training for Feature Alignment on pairs (image & caption). Only the adapter is training, based on a subset of CC3M and COCO.
-
Stage 2: Fine-tuning End-to-End on multimodal dialogues.
Both the projection and LLM are updated using a mix of instructive data, the data consists of two parts: Russian-language and English-language dialogues. The dataset has the following structure:
SFT Datasets Task Caption VQA WebQA OCRQA Conversation DocVQA Text-only SFT Dataset source ShareGPT4V COC, SAM-9K WebData TextVQA, OCRVQA LLaVA-v1.5-665k, OCRVQA Proprietary data (ru) Proprietary data (ru), Alpaca (en) #Samples 100K 20K, 9K 1.5K 120K 665K 20K 10K