Задача
Создание ассистента для извлечения метаданных из научной публикации и последующих ответов на основе извлеченной информации.
- Извлечь из статьи метаданные в формате Json для дальнейшего использования.
- Провести семантический анализ.
- Провести морфологический анализ и дедубликацию
В качестве примера, создаём агентов на базовом MAESTRO, Langchain и ReAct.
Планирование
Определить множества типов ввода и вывода ассистента
Ввод
- pdf-файл научной публикации
Вывод
- json-файл с метаданными по этой публикации
- Текст ответа на вопрос пользователя по извлеченным метаданным
Определить примерную последовательность работы ассистента
- Извлечение текста из pdf-файла
- Обработка извлеченного текста с помощью LLM для получения необходимых метаданных
- Ответ на вопрос по извлеченным метаданным
Определить необходимые для создания и уже имеющиеся в кодовой базе компоненты
- DocumentExtractor - существующий компонент - OCR сервис для извлечения текста и его структуры из файла
- MetadataExtractor - новый компонент (Базовый) - сервис для извлечения метаданных на MAESTRO
- LangchainExtractor - новый компонент (Langchain) - сервис для извлечения метаданных на Langchain
- ReactExtractor - новый компонент (ReAct) - сервис для извлечения метаданных на ReAct
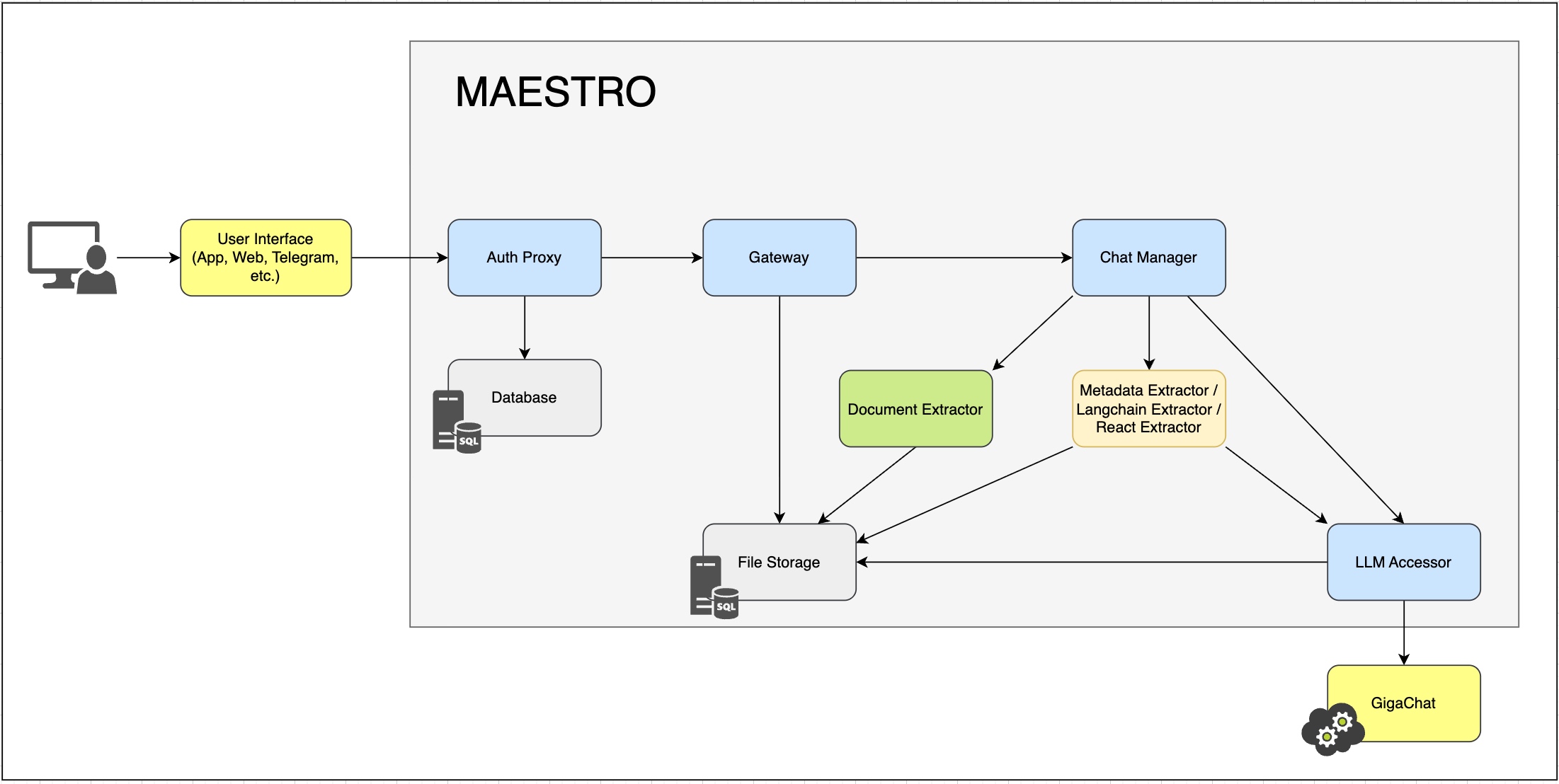
Определить примерный набор функций, вызываемых по ходу диалога
- Ввод: pdf-файл, вывод: txt-файл
- Ввод: txt-файл, вывод: json-файл с метаданными
- Ввод: вопрос пользователя, вывод: ответ LLM
Создание трека на базовом MAESTRO
Создание компонентов
Инициализировать необходимые компоненты
- Инициализация с помощью существующего шаблона сервисов
- Указание имени нового компонента metadata-extractor
Определить ввод и вывод нового компонента
- DocumentExtractor возвращает текстовый файл со структурой, значит на вход в MetadataExtractor будет подаваться файл
- На выходе ассистента должен быть json-файл, значит MetadataExtractor должен возвращать файл или текст
Определить тип API grpc-сервиса, наиболее подходящий для ввода и вывода
- Для ввода в виде файла и вывода в виде файла наиболее подходит `ContentInterpreterAPI` в библиотеке `mmar_mapi`, модуль `mmar_mapi.services`
В сгенерированном с помощью шаблона коде указать выбранный тип API grpc-сервиса
- В файле `src/metadata_extractor/metadata_extractor.py` класс `MetadataExtractor` наследует класс `ContentInterpreterAPI`
- Определить метод `interpret`, необходимый для `ContentInterpreterAPI`
Реализовать часть кода, относящуюся к непосредственной логике работы компоненты
- Написать логику метода `interpret` в соответствии с определенными типами ввода и вывода
- Параметры конфигурации указать в файле `src/metadata_extractor/config.py` в виде pydantic-моделей
Сборка компонентов в трек
Инициализировать новый трек
- Создать файл `chat-manager-playground/src/chat_manager_playground/tracks/metadata_extraction.py`
Определить тип нового трека
- Библиотекой `mmar_mapi` в модуле `mmar_mapi.tracks` на выбор предоставляется два типа:
- `SimpleTrack` - класс для простого взаимодействия типа запрос-ответ
- `StateActionPolicyTrack` - класс для комплексного взаимодействия с выбором состояния, зависящего от запроса, и выбором действия агента в зависимости от состояния.
- Для последовательности работы агента, подходит класс `SimpleTrack`
- В созданном файле `metadata_extraction.py` определить класс `MetadataExtraction(SimpleTrack)`
Инициализировать grpc-клиенты используемых треком компонентов
- Указать домен трека `DOMAIN = DOMAINS.science`
- Указать отображаемое имя трека`CAPTION = "Метаданные публикации"`
- В конструкторе класса `MetadataExtraction` с помощью библиотеки `mmar_ptag` указать
def __init__(self, config: Config): self.config = config self.document_extractor = ptag_client( DocumentExtractorAPI, config.addresses.document_extractor ) self.metadata_extractor = ptag_client( ContentInterpreterAPI, config.addresses.metadata_extractor )
Реализовать последовательность вызовов компонентов ассистента
- Реализовать метод `generate_response` класса `MetadataExtraction`
- Вызов DocumentExtractor на входящий файл - получение файла со структурой текста
- Вызов MetadataExtractor на файл с текстом - получение json с метаданными
- Вызов MetadataExtractor на текст вопроса - получение текста ответа
- в качестве примера можно взять содержимое файла `chat-manager-playground/src/chat_manager_playground/tracks/simple.py`
Создание трека на Langchain
Создание компонентов
Инициализировать необходимые компоненты
- Инициализация с помощью существующего шаблона сервисов
- Указание имени нового компонента langchain-extractor
Определить ввод и вывод нового компонента
- DocumentExtractor возвращает текстовый файл со структурой, значит на вход в LangchainExtractor будет подаваться файл
- На выходе ассистента должен быть json-файл, значит LangchainExtractor должен возвращать файл или текст
Определить тип API grpc-сервиса, наиболее подходящий для ввода и вывода
- Для ввода в виде файла и вывода в виде файла наиболее подходит `ContentInterpreterAPI` в библиотеке `mmar_mapi`, модуль `mmar_mapi.services`
В сгенерированном с помощью шаблона коде указать выбранный тип API grpc-сервиса
- В файле `src/langchain_extractor/langchain_extractor.py` класс `LangchainExtractor` наследует класс `ContentInterpreterAPI`
- Определить метод `interpret`, необходимый для `ContentInterpreterAPI`
Реализовать часть кода, относящуюся к непосредственной логике работы компоненты
- Написать логику метода `interpret` в соответствии с определенными типами ввода и вывода
- Параметры конфигурации указать в файле `src/langchain_extractor/config.py` в виде pydantic-моделей
Сборка компонентов в трек
Инициализировать новый трек
- Создать файл `chat-manager-playground/src/chat_manager_playground/tracks/langchain_extraction.py`
Определить тип нового трека
- Библиотекой `mmar_mapi` в модуле `mmar_mapi.tracks` на выбор предоставляется два типа:
- `SimpleTrack` - класс для простого взаимодействия типа запрос-ответ
- `StateActionPolicyTrack` - класс для комплексного взаимодействия с выбором состояния, зависящего от запроса, и выбором действия агента в зависимости от состояния.
- Для последовательности работы агента, подходит класс `SimpleTrack`
- В созданном файле `langchain_extraction.py` определить класс `LangchainExtraction(SimpleTrack)`
Инициализировать grpc-клиенты используемых треком компонентов
- Указать домен трека `DOMAIN = DOMAINS.science`
- Указать отображаемое имя трека`CAPTION = "Метаданные публикации"`
- В конструкторе класса `LangchainExtraction` с помощью библиотеки `mmar_ptag` указать
def __init__(self, config: Config): self.config = config self.document_extractor = ptag_client( DocumentExtractorAPI, config.addresses.document_extractor ) self.langchain_extractor = ptag_client( ContentInterpreterAPI, config.addresses.langchain_extractor )
Реализовать последовательность вызовов компонентов ассистента
- Реализовать метод `generate_response` класса `LangchainExtraction`
- Вызов DocumentExtractor на входящий файл - получение файла со структурой текста
- Вызов LangchainExtractor на файл с текстом - получение json с метаданными
- Вызов LangchainExtractor на текст вопроса - получение текста ответа
- в качестве примера можно взять содержимое файла `chat-manager-playground/src/chat_manager_playground/tracks/simple.py`
Создание трека на ReAct
Создание компонентов
Инициализировать необходимые компоненты
- Инициализация с помощью существующего шаблона сервисов
- Указание имени нового компонента react-extractor
Определить ввод и вывод нового компонента
- DocumentExtractor возвращает текстовый файл со структурой, значит на вход в ReactExtractor будет подаваться файл
- На выходе ассистента должен быть json-файл, значит ReactExtractor должен возвращать файл или текст
Определить тип API grpc-сервиса, наиболее подходящий для ввода и вывода
- Для ввода в виде файла и вывода в виде файла наиболее подходит `ContentInterpreterAPI` в библиотеке `mmar_mapi`, модуль `mmar_mapi.services`
В сгенерированном с помощью шаблона коде указать выбранный тип API grpc-сервиса
- В файле `src/react_extractor/react_extractor.py` класс `ReactExtractor` наследует класс `ContentInterpreterAPI`
- Определить метод `interpret`, необходимый для `ContentInterpreterAPI`
Реализовать часть кода, относящуюся к непосредственной логике работы компоненты
- Написать логику метода `interpret` в соответствии с определенными типами ввода и вывода
- Параметры конфигурации указать в файле `src/react_extractor/config.py` в виде pydantic-моделей
Сборка компонентов в трек
Инициализировать новый трек
- Создать файл `chat-manager-playground/src/chat_manager_playground/tracks/react_extraction.py`
Определить тип нового трека
- Библиотекой `mmar_mapi` в модуле `mmar_mapi.tracks` на выбор предоставляется два типа:
- `SimpleTrack` - класс для простого взаимодействия типа запрос-ответ
- `StateActionPolicyTrack` - класс для комплексного взаимодействия с выбором состояния, зависящего от запроса, и выбором действия агента в зависимости от состояния.
- `PromptToolTrack` - класс для ReAct-взаимодействия с LLM, определяемый набором вызываемых функций и системным промптом..
- Для последовательности работы агента, подходит класс `PromptToolTrack`
- В созданном файле `react_extraction.py` определить класс `ReactExtraction(PromptToolTrack)`
Реализовать вызываемые функции, и их описания.
Удобной оберткой будет класс `ToolBelt`.
- В конструкторе класса `ToolBelt` с помощью библиотеки `mmar_ptag` указать
def __init__(self, config: Config):
self.config = config
self.document_extractor = ptag_client(
DocumentExtractorAPI, config.addresses.document_extractor
)
self.react_extractor = ptag_client(
ContentInterpreterAPI,
config.addresses.react_extractor
)
- Ввод: `resource_id` pdf-файла, вывод: `resource_id` txt-файла
- Вызывает внутри себя`DocumentExtractor`
- Ввод: `resource_id` txt-файла, вывод: `resource_id` json-файла
- Вызывает внутри себя`ReactExtractor`
- Ввод: (`question`, `resource_id` json-файла), вывод: ответ LLM
Инициализировать ReAct трек
- Указать домен трека `DOMAIN = DOMAINS.science`
- Указать отображаемое имя трека`CAPTION = "Метаданные публикации"`
- Указать системный промпт для трека
- Указать набор вызываемых функций из экземпляра класса `ToolBelt`
Сервис Document Extractor
Сервис распознавания текста из документов и изображений для цифрового помощника.
Возможности
- Чтение PDF с текстовым слоем
- OCR текста с изображений
- OCR PDF-сканов
- Извлечение таблиц в Markdown
- Описания изображений VLM (скоро)
Быстрый старт
Линтеры
pip install black flake8-pyproject mypy
# Автоформатирование
black .
# Проверка
flake8
mypy .
или через pre-commit
pip install pre-commit
pre-commit install
pre-commit run --all-files # проверка вручную
Развёртывание
Dev:
sudo docker-compose -f docker-compose-dev.yaml up --buildProd:
sudo docker-compose -f docker-compose-dev.yaml up --buildЗависимости
# Ubuntu/Debian
sudo apt install tesseract-ocr-rus tesseract-ocr-eng -y
# Python 3.13
python3.13 -m pip install -r requirements.txt
Конфигурация приложения
# Отредактируйте под вашу среду
src/config.py
Примеры API вызовов
POST /ocr/text
Content-Type: multipart/form-data
file: /path/to/document.pdf
Response: {"text": "распознанный текст"}
POST /ocr/table
file: /path/to/table.pdf
Response: {"markdown": "| Col1 | Col2 |\n|------|------|\n| val | val |"}
Библиотека mmar-mapi
Мультимодальные архитектуры Maestro API - Python-библиотека, предоставляющая базовые утилиты для создания систем разговорного ИИ, с особым акцентом на медицинские/здравоохранные приложения
Возможности
- Управление чатами: Фреймворк для управления разговорами с гибкими типами сообщений
- Хранение файлов: Управление ресурсами с поддержкой дедупликации
- Обработка документов: Извлечение контента из различных типов документов
- Интеграция LLM: Интерфейсы для коммуникации с большими языковыми моделями
- Парсинг XML: Утилиты для медицинских диагностических данных
Быстрый старт
from mmar_mapi import Chat, HumanMessage, AIMessage, make_content
# Создание сессии чата
chat = Chat(
context=Context(session_id="session-123", user_id="user-456"),
messages=[
HumanMessage(content=make_content("Привет, AI!")),
AIMessage(content=make_content("Чем я могу тебе сегодня помочь?"))
]
)
from mmar_mapi import FileStorage, ResourceId
# Хранение и получение файлов
storage = FileStorage()
resource_id = storage.upload(b"file content")
content = storage.download(resource_id)
Основные модули
Система чатов (mmar_mapi.models.chat)
Chat- Контейнер для разговора с контекстом и сообщениямиHumanMessage,AIMessage,MiscMessage- Типы сообщенийContent- Гибкий контент с поддержкой текста, ресурсов, команд и виджетовWidget- UI-компоненты для интерактивных разговоров
Хранение файлов (mmar_mapi.file_storage)
FileStorageAPI- Абстрактный интерфейс для операций с файламиFileStorage- Реализация с дедупликациейFileStorageBasic- Простой доступ к файлам без хранилищаResourceId- Типобезопасные идентификаторы ресурсов
Модели (mmar_mapi.models)
TrackInfo,DomainInfo- Категоризация треков и доменовDiagnosticsXMLTagEnum,MTRSXMLTagEnum,UncertaintyXMLTagEnum- Медицинские XML теги
Утилиты (mmar_mapi.utils)
make_session_id()- Генератор уникальных идентификаторов сессийchunked()- Разделение итерируемых объектов на чанкиXMLParser- Утилита парсинга XML
Сервисы (mmar_mapi.services)
Сервисные API для интеграции с внешними системами:
LLM Hub (llm_hub.py)
LLMHubAPI- Интерфейс для коммуникации с LLMLLMCallProps- Конфигурация вызоваLLMPayload- Полезная нагрузка сообщения с вложениямиLLMResponseExt- Расширенный формат ответа
Document Extractor (document_extractor.py)
DocumentExtractorAPI- Извлечение контента из документовDocExtractionSpec- Конфигурация извлеченияExtractedTable,ExtractedPicture,ExtractedPageImage- Результаты извлечения
Chat Manager (chat_manager.py)
ChatManagerAPI- Управление доменами, треками и ответами чата
Text Processing (text_generator.py, text_processor.py)
TextGeneratorAPI- Генерация текста из чатаTextProcessorAPI- Обработка текста с контекстом чата
Content Interpreter (content_interpreter.py)
ContentInterpreterAPI- Интерпретация ресурсов контентаContentInterpreterRemoteAPI- Удалённая интерпретация контентаContentInterpreterRemoteResponse- Формат удалённого ответа
Дополнительные сервисы
BinaryClassifiersAPI- Двоичная классификация текстаTranslatorAPI- ПереводCriticAPI- Оценка текстаTextExtractorAPI- Извлечение текста из ресурсов
Библиотека mmar-ptag
Фреймворк pydantically-type-adapted-grpc для команды мультимодальных архитектур
Основная цель: упростить определение типобезопасных Python-интерфейсов для разделённых сервисов.
Возможности
- Типобезопасный RPC с использованием Pydantic для валидации
- Автоматическое переподключение с настраиваемым количеством попыток повтора
- Встроенная трассировка с поддержкой trace ID
- Дизайн на основе интерфейсов - определение сервисов как Python-классов
- Аргументы только по ключевым словам - явный и читаемый API
Быстрый старт
Установка
pip install mmar-ptagОпределение сервиса
from types import SimpleNamespace
from mmar_ptag import deploy_server
class Greeter:
def say_hello(self, *, name: str, count: int = 1, trace_id: str = "") -> dict:
return {"message": f"Hello, {name} x{count}"}
Запуск сервера
deploy_server(
config_server=SimpleNamespace(port=50051, max_workers=10),
service=Greeter()
)
Создание клиента
from mmar_ptag import ptag_client
class Greeter:
def say_hello(self, *, name: str, count: int = 1) -> dict:
...
client = ptag_client(Greeter, "localhost:50051")
result = client.say_hello(name="World", count=3)
print(result) # {'message': 'Hello, World x3'}
Примеры использования
Простой RPC вызов
from mmar_ptag import ptag_client
class Greeter:
def say_hello(self, *, name: str, count: int = 1) -> dict:
...
client = ptag_client(Greeter, "localhost:50051")
result = client.say_hello(name="World", count=3)
print(result) # {'message': 'Hello, World x3'}
Поддержка Trace ID
from mmar_ptag import ptag_client
class UserService:
def get_user(self, *, user_id: int, trace_id: str = "") -> dict:
...
client = ptag_client(UserService, "localhost:50051")
# Trace ID автоматически передаётся по всей цепочке вызовов
result = client.get_user(user_id=123, trace_id="request-abc-123")
Как это работаеа
ptag использует адаптеры Pydantic для обработки преобразования типов между Python и gRPC/protobuf.
Example: client.say_hello(name="World", count=3)
Поток клиента (отправка запроса):
{name="World", count=3}
-(args tuple)->
("World", 3)
-(args_adapter.dump_json)->
["World", 3]
-(wrap in PTAGRequest)->
b'\n\tsay_hello\x12\x0c["World", 3]'
-(server receives)->
Поток сервера (обработка и ответ):
b'\n\tsay_hello\x12\x0c["World", 3]'
-(args_adapter.validate_json)->
["World", 3]
-(bind to kwargs)->
{name="World", count=3}
-(say_hello method)->
{"message": "Hello, World x3"}
-(result_adapter.dump_json)->
{"message": "Hello, World x3"}
-(wrap in PTAGResponse)->
b'\n\tsay_hello\x12\x1e{"message": "Hello, World x3"}'
-(client receives)->
Поток клиента (получение ответа):
b'\n\tsay_hello\x12\x1e{"message": "Hello, World x3"}'
-(return_adapter.validate_json)->
{"message": "Hello, World x3"}
Это обеспечивает:
- Аргументы валидируются и сериализуются перед отправкой
- Возвращаемые значения десериализуются и валидируются после получения
- Типобезопасность по всему каналу без ручных определений protobuf
Справочник API
ptag_client(interface, address, reconnect_attempts=5)
Создаёт динамического клиента для заданного интерфейса по указанному gRPC-адресу.
interface: Тип (класс), определяющий интерфейс сервисаaddress: Адрес gRPC-сервера (например,"localhost:50051")reconnect_attempts: Количество попыток переподключения при сбое соединения (по умолчанию: 5)
ptag_attach(server, service_object)
Подключает объект сервиса к существующему gRPC-серверу.