Описание
MAESTRO (МАЭСТРО) представляет собой фреймворк, который позволяет с лёгкостью интегрировать в вашу систему агентов на базе большинства популярных LLM, включая российские, а также настраивать их роли и взаимодействие.
Устройство фреймворка
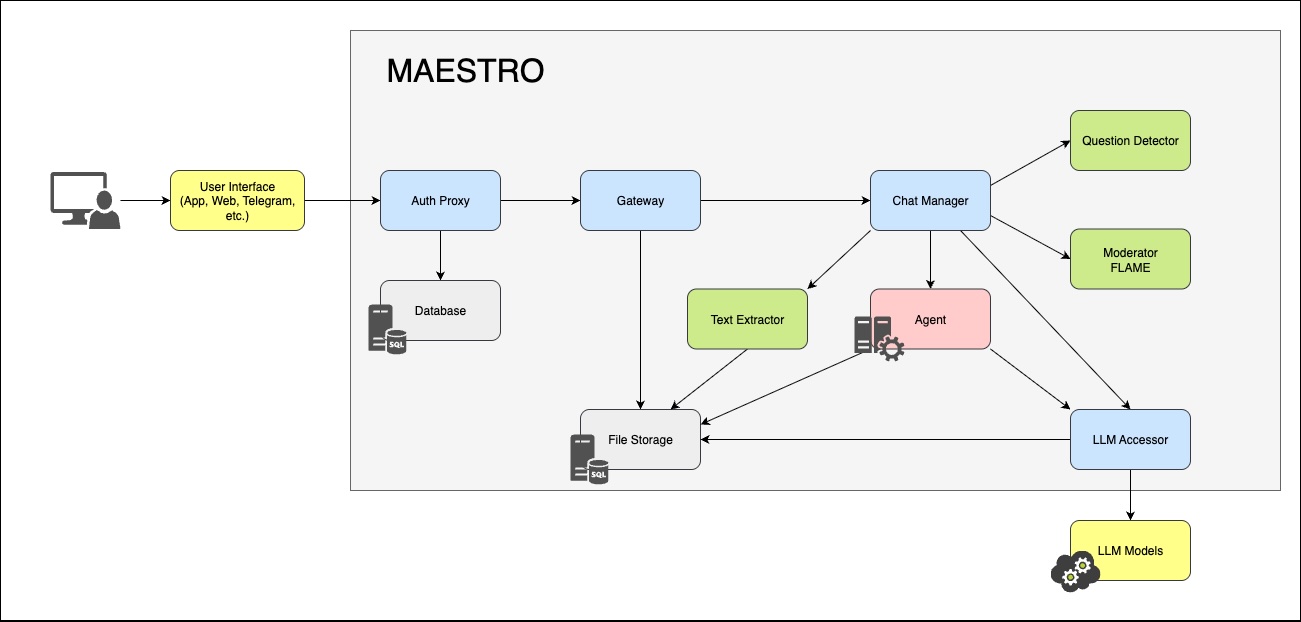
- авторизация и управление ролями
- хранение состояния диалога
- взаимодействие с выбранной LLM (включая Гигачат)
- оркестрация вызовов агентов и инструментов в ходе диалога
- модерация и цензурирование реплик
- упрощение интеграции агентов
- логирование операций
| Библиотека | Использование |
|---|---|
mmar-mapi |
API Маэстро |
mmar-utils |
Утилиты для Маэстро |
mmar-llm |
Взаимодействие с LLM (в т.ч. Гигачат) |
mmar-ptag |
Взаимодействие между сервисами по gRPC |
mmar-flame |
Гибкая модерация |
mmar-carl |
Построение цепочек рассуждений |
| Категория | Технологии |
|---|---|
| Средства контейнеризации | Docker, Docker Compose |
| Используемый язык | Python 3.12+ |
| Хранение данных | Файловая система, PostgreSQL 12+ |
| Используемые библиотеки |
|
Пример: создание ассистента
Создание ассистента для извлечения метаданных из научной публикации и последующих ответов на основе извлеченной информации.
В качестве примера, создаём агентов на базовом MAESTRO, Langchain и ReAct.
Пример доступен по ссылке Создание ассистента в рамках MAESTRO
Цепочки рассуждений с использованием CARL
CARL (Collaborative Agent Reasoning Library) — библиотека для формализации экспертного мышления на основе триады Event-Action-Result. Позволяет преобразовывать сложные мыслительные процессы в понятную для LLM форму с поддержкой параллельного выполнения и интеллектуального извлечения контекста.
Описание методологии
Цепочки рассуждений — это структурированный подход к формализации экспертного мышления, основанный на триаде Event-Action-Result. Методология позволяет преобразовать сложные мыслительные процессы экспертов в понятную для LLM форму, создавая основу для интеллектуальных агентных систем.
Event обозначает исходное событие, факт или действие, которое инициирует процесс рассуждения. Action отражает ответную деятельность системы или эксперта, включая уточнения, анализ и назначение процедур. Result показывает конечный вывод на каждом шаге, будь то полученная информация, промежуточное заключение или корректировка стратегии.
Библиотека MMAR CARL
Для практической реализации цепочек рассуждений разработана специализированная библиотека MMAR CARL (Collaborative Agent Reasoning Library) — универсальный инструмент для построения систем экспертного мышления с поддержкой:
- RAG-подобного извлечения контекста — автоматическое извлечение релевантной информации из входных данных для каждого шага рассуждений
- Параллельного выполнения на основе DAG — автоматическая оптимизация последовательности выполнения с учётом зависимостей между шагами
- Мультиязычности — встроенная поддержка русского и английского языков
- Универсальной архитектуры — применимость к любой предметной области
Ключевые компоненты
- StepDescription — формализует шаг рассуждений с указанием цели, вопросов для анализа, запросов для извлечения контекста и зависимостей от предыдущих шагов.
- ReasoningChain — управляет последовательностью выполнения шагов с автоматической параллелизацией независимых операций.
- ReasoningContext — содержит исходные данные, конфигурацию LLM и историю выполнения.
Полный пример: Медицинская диагностика
import asyncio
from mmar_carl import (
ReasoningChain, StepDescription, ReasoningContext,
Language, ContextSearchConfig
)
from mmar_llm import EntrypointsAccessor, EntrypointsConfig
import json
# Создание EntrypointsAccessor
def create_entrypoints(entrypoints_path: str):
with open(entrypoints_path, encoding="utf-8") as f:
config_data = json.load(f)
entrypoints_config = EntrypointsConfig.model_validate(config_data)
return EntrypointsAccessor(entrypoints_config)
# Определение цепочки медицинских рассуждений
CLINICAL_REASONING = [
StepDescription(
number=1,
title="Сбор жалоб и анамнеза",
aim="Систематизировать клиническую картину",
reasoning_questions="Какие симптомы указывают на возможные диагнозы?",
step_context_queries=[
"основные жалобы",
"длительность симптомов",
"факторы риска"
],
stage_action="Формирование предварительных гипотез",
example_reasoning="Характер и динамика симптомов определяют направление диагностического поиска"
),
StepDescription(
number=2,
title="Анализ объективных данных",
aim="Оценить результаты обследований",
reasoning_questions="Какие объективные признаки подтверждают гипотезы?",
dependencies=[1], # Зависит от шага 1
step_context_queries=[
"результаты осмотра",
"лабораторные показатели",
"инструментальные данные"
],
stage_action="Сопоставить субъективные и объективные данные",
example_reasoning="Лабораторные показатели коррелируют с клинической картиной"
),
StepDescription(
number=3,
title="Формирование диагностического заключения",
aim="Установить окончательный диагноз",
reasoning_questions="Какой диагноз наиболее вероятен?",
dependencies=[1, 2], # Зависит от шагов 1 и 2
step_context_queries=[
"клинические рекомендации",
"дифференциальная диагностика",
"критерии постановки диагноза"
],
stage_action="Синтезировать диагностическое заключение",
example_reasoning="Диагноз устанавливается на основе совокупности клинических и лабораторных данных"
)
]
# Конфигурация поиска контекста
search_config = ContextSearchConfig(
strategy="vector", # Семантический поиск
vector_config={
"similarity_threshold": 0.75,
"max_results": 5
}
)
# Создание цепочки рассуждений
chain = ReasoningChain(
steps=CLINICAL_REASONING,
search_config=search_config,
max_workers=2,
enable_progress=True
)
# Медицинские данные пациента
patient_data = """
Пациент: мужчина, 45 лет
Основные жалобы: боли в грудной клетке давящего характера,
одышка при физической нагрузке
Длительность симптомов: 2 недели
Факторы риска: курение 20 лет, артериальная гипертензия
Результаты осмотра: АД 160/95, ЧСС 88, хрипы в лёгких отсутствуют
Лабораторные показатели: холестерин ЛПНП 4.9 ммоль/л, тропонин отрицательный
Инструментальные данные: ЭКГ - признаки гипертрофии левого желудочка
"""
# Инициализация контекста
entrypoints = create_entrypoints("entrypoints.json")
context = ReasoningContext(
outer_context=patient_data,
entrypoints=entrypoints,
entrypoint_key="gigachat-2-max",
language=Language.RUSSIAN,
retry_max=3
)
# Выполнение цепочки рассуждений
result = chain.execute(context)
# Получение результатов
print("=== Диагностическое заключение ===")
print(result.get_final_output())
print("\n=== Результаты по шагам ===")
for step_num, step_result in result.step_results.items():
print(f"\nШаг {step_num}: {step_result}")Конфигурация поиска контекста
CARL поддерживает два режима извлечения релевантной информации:
Подстроковый поиск
from mmar_carl import ContextSearchConfig, ReasoningChain
search_config = ContextSearchConfig(
strategy="substring",
substring_config={
"case_sensitive": False, # Регистронезависимый поиск
"min_word_length": 3, # Минимальная длина слова
"max_matches_per_query": 5 # Максимум результатов на запрос
}
)
chain = ReasoningChain(
steps=steps,
search_config=search_config
)Векторный поиск
search_config = ContextSearchConfig(
strategy="vector",
vector_config={
"similarity_threshold": 0.7,
"max_results": 5
}
)Преимущества использования CARL
- 🎯 Формализация экспертного мышления — структурированное представление сложных рассуждений
- ⚡ Автоматическая оптимизация — параллельное выполнение независимых шагов
- 🔍 Интеллектуальное извлечение контекста — RAG-подобный поиск релевантной информации
- 🌍 Многоязычность — встроенная поддержка русского и английского
- 🏗️ Универсальность — применимость к любой предметной области (медицина, юриспруденция, финансы)
- ⚙️ Готовность к продуктовой разработке — обработка ошибок, повторные попытки, мониторинг
Пример использования
import asyncio
from mmar_carl import (
ReasoningChain, StepDescription, ReasoningContext,
Language, ContextSearchConfig
)
from mmar_llm import EntrypointsAccessor, EntrypointsConfig
import json
# Определение цепочки медицинских рассуждений
CLINICAL_REASONING = [
StepDescription(
number=1,
title="Сбор жалоб и анамнеза",
aim="Систематизировать клиническую картину",
reasoning_questions="Какие симптомы указывают на возможные диагнозы?",
step_context_queries=[
"основные жалобы",
"длительность симптомов",
"факторы риска"
],
stage_action="Формирование предварительных гипотез",
example_reasoning="Характер и динамика симптомов определяют направление диагностического поиска"
)
]
# Создание цепочки рассуждений
chain = ReasoningChain(
steps=CLINICAL_REASONING,
search_config=search_config,
max_workers=2,
enable_progress=True
)
# Выполнение цепочки рассуждений
result = chain.execute(context)Работа с результатами выполнения цепочек
После выполнения цепочки рассуждений метод execute() возвращает объект ReasoningResult, который содержит полную информацию о выполнении всех шагов.
class ReasoningResult:
success: bool # Общий успех выполнения
history: list[str] # Полная история рассуждений
step_results: list[StepExecutionResult] # Результаты каждого шага
total_execution_time: float | None # Общее время выполнения
metadata: dict[str, Any] # Дополнительные метаданные
Каждый шаг возвращает детальную информацию о своем выполнении:
class StepExecutionResult:
step_number: int # Номер шага
step_title: str # Название шага
result: str # Результат от LLM
success: bool # Успешность выполнения
error_message: str | None # Сообщение об ошибке
execution_time: float | None # Время выполнения в секундах
updated_history: list[str] # История после этого шага
Получение финального результата
get_final_output() -- возвращает только текст последнего шага без служебных заголовков:
result = chain.execute(context)
# Получить только вывод финального шага
final_answer = result.get_final_output()
print(final_answer)
Пример вывода:
На основании клинической картины и результатов обследования у пациента диагностируется артериальная гипертензия II степени с высоким риском сердечно-сосудистых осложнений...
Получение полной истории
get_full_output() -- возвращает полную историю выполнения со всеми шагами:
# Получить всю историю рассуждений
full_history = result.get_full_output()
print(full_history)
Пример вывода:
Шаг 1. Сбор жалоб и анамнеза
Результат: Пациент предъявляет жалобы на боли в грудной клетке...
Шаг 2. Анализ объективных данных
Результат: При объективном изучении анализов выявлены следующие отклонения...
Шаг 3. Формирование диагностического заключения
Результат: На основании клинической картины...
Работа с результатами отдельных шагов
step_results -- список объектов StepExecutionResult для каждого шага:
# Итерация по результатам каждого шага
for step in result.step_results:
print(f"Шаг {step.step_number}: {step.step_title}")
print(f"Статус: {'✓' if step.success else '✗'}")
print(f"Время выполнения: {step.execution_time:.2f}с")
print(f"Результат: {step.result}\n")
Фильтрация успешных и неуспешных шагов
get_successful_steps() -- возвращает только успешно выполненные шаги:
successful = result.get_successful_steps()
print(f"Успешно выполнено: {len(successful)} шагов")
get_failed_steps() -- возвращает шаги с ошибками:
failed = result.get_failed_steps()
if failed:
print("Ошибки выполнения:")
for step in failed:
print(f" Шаг {step.step_number}: {step.error_message}")
Сравнение методов получения результата
| Метод | Назначение | Формат вывода |
|---|---|---|
get_final_output() |
Только финальный ответ | Чистый текст без заголовков |
get_full_output() |
Полная история | Текст со всеми шагами и заголовками |
step_results |
Доступ к отдельным шагам | Список объектов StepExecutionResult |
history |
Прямой доступ к истории | Список строк |
get_successful_steps() |
Только успешные шаги | Список успешных StepExecutionResult |
get_failed_steps() |
Только шаги с ошибками | Список неуспешных StepExecutionResult |
Рекомендации по использованию
- Для продуктовых приложений используйте
get_final_output()для отображения конечного результата пользователю и использования результата в узлах мультиагентных систем - Для отладки применяйте
get_full_output()и детальный анализstep_results - Для мониторинга отслеживайте
success,execution_timeиmetadata - Для логирования сохраняйте полную
historyи информацию об ошибках - Для аналитики используйте метаданные из
result.metadataдля анализа производительности
Пример 1: Базовая обработка результата
result = chain.execute(context)
# Проверка успешности
if result.success:
print("✓ Цепочка выполнена успешно")
print(f"Общее время: {result.total_execution_time:.2f}с")
print(f"\nФинальный результат:\n{result.get_final_output()}")
else:
print("✗ Выполнение завершилось с ошибками")
for failed_step in result.get_failed_steps():
print(f" Шаг {failed_step.step_number}: {failed_step.error_message}")
Пример 2: Детальный анализ выполнения
result = chain.execute(context)
print("=== СТАТИСТИКА ВЫПОЛНЕНИЯ ===")
print(f"Всего шагов: {len(result.step_results)}")
print(f"Успешных: {len(result.get_successful_steps())}")
print(f"Неуспешных: {len(result.get_failed_steps())}")
print(f"Общее время: {result.total_execution_time:.2f}с")
# Детальная информация по каждому шагу
print("\n=== РЕЗУЛЬТАТЫ ПО ШАГАМ ===")
for step in result.step_results:
status = "✓ УСПЕХ" if step.success else "✗ ОШИБКА"
print(f"\n[{status}] Шаг {step.step_number}: {step.step_title}")
print(f"Время: {step.execution_time:.2f}с")
if step.success:
# Показать первые 200 символов результата
preview = step.result[:200] + "..." if len(step.result) > 200 else step.result
print(f"Результат: {preview}")
else:
print(f"Ошибка: {step.error_message}")
Пример 3: Работа с метаданными
result = chain.execute(context)
# Получение статистики выполнения
if "execution_stats" in result.metadata:
stats = result.metadata["execution_stats"]
print("=== СТАТИСТИКА ПАРАЛЛЕЛИЗАЦИИ ===")
print(f"Параллельных батчей: {stats['parallel_batches']}")
print(f"Всего шагов: {stats['total_steps']}")
print(f"Выполнено: {stats['executed_steps']}")
print(f"Ошибок: {stats['failed_steps']}")
Пример 4: Доступ к истории выполнения
Атрибут history содержит список строк с результатами каждого шага в порядке выполнения:
result = chain.execute(context)
# Получить историю как список
for i, entry in enumerate(result.history, 1):
print(f"\n--- Запись {i} ---")
print(entry)
# Или как одну строку
full_text = result.get_full_output()
Пример 5: Обработка ошибок
При возникновении ошибок в процессе выполнения:
result = chain.execute(context)
if not result.success:
print("⚠ Обнаружены ошибки в выполнении цепочки")
# Получить все неуспешные шаги
failed_steps = result.get_failed_steps()
for step in failed_steps:
print(f"\nОшибка на шаге {step.step_number}: {step.step_title}")
print(f"Сообщение: {step.error_message}")
# Вывести последнюю успешную запись в истории
if step.updated_history:
print(f"Последняя история: {step.updated_history[-1][:100]}...")
# Получить частичные результаты успешных шагов
successful_steps = result.get_successful_steps()
print(f"\nУспешно завершено {len(successful_steps)} из {len(result.step_results)} шагов")
Пример 6: Интеграция с системой логирования
import logging
logger = logging.getLogger(__name__)
result = chain.execute(context)
# Логирование результатов
logger.info(f"Chain execution completed: success={result.success}")
logger.info(f"Total execution time: {result.total_execution_time:.2f}s")
for step in result.step_results:
if step.success:
logger.debug(f"Step {step.step_number} succeeded in {step.execution_time:.2f}s")
else:
logger.error(f"Step {step.step_number} failed: {step.error_message}")
# Сохранение финального результата
logger.info(f"Final output: {result.get_final_output()}")
Сервис авторизации
AuthService — модуль аутентификации и авторизации, поддерживающий два типа клиентов: пользователей (через email/пароль) и клиентские приложения (через client_id/client_secret). Использует JWT-токены с временем жизни и защиту от перебора через reCAPTCHA.
Описание
AuthService — это полнофункциональный модуль аутентификации, который предоставляет гибкую систему авторизации для различных типов клиентов. Сервис поддерживает два основных сценария работы: авторизация конечных пользователей через email и пароль, и авторизация клиентских приложений через пару client_id/client_secret.
Для защиты от автоматических атак и брутфорса система интегрирована с Google reCAPTCHA, которая может быть включена или отключена в конфигурации. Все пароли хэшируются с использованием современного алгоритма хэширования перед сохранением в базу данных.
Сервис использует JWT (JSON Web Tokens) для управления сессиями пользователей. Токены содержат полезную нагрузку с информацией о клиенте, пользователе и типе авторизации, а также временем expiration. Каждый токен сохраняется в базе данных для возможности принудительного завершения сессий.
Основные методы API
class AuthService:
async def register(self, data: V1RegisterRequest, external_id: str | None = None) -> list
async def login(self, form: LoginForm) -> V1JWTResponse
async def login_client(self, form: ClientLoginForm) -> V1JWTResponse
async def identify(self, auth_header: str) -> dict
async def get_info_about_me(self, auth_header: str) -> V1Me
async def refresh(self, auth_header: str) -> V1JWTResponse
async def logout(self, auth_header: str) -> V1JWTResponse
Типы авторизации
Сервис поддерживает два механизма авторизации:
- Bearer Token — для авторизации пользователей через JWT-токены
- Basic Auth — для авторизации клиентских приложений через client_id/client_secret
Пользовательская авторизация:
# Заголовок для пользовательской авторизации
Authorization: Bearer eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9...
Клиентская авторизация:
# Заголовок для клиентской авторизации
Authorization: Basic Y2xpZW50X2lkOmNsaWVudF9zZWNyZXQ=
Меры безопасности
- Хэширование паролей — все пароли хэшируются перед сохранением
- reCAPTCHA — защита от автоматической регистрации и брутфорса
- JWT с expiration — ограниченное время жизни токенов
- Валидация email — приведение email к нижнему регистру
- Проверка активности пользователя — только активные пользователи могут авторизоваться
- Client Secret Hole — дополнительный механизм для генерации client_secret на основе client_id
Модели данных
class V1RegisterRequest:
email: str
password: str
full_name: str
where_from: str
why_access: str
captcha: str
client_id: str
class LoginForm:
email: str
password: str
class ClientLoginForm:
client_id: str
client_secret: str
class V1JWTResponse:
access_token: str
token_type: str = "bearer"
Обработка ошибок
Сервис выбрасывает стандартизированные исключения:
FailedToRegisterException— ошибка регистрации (непройденная капча, некорректные данные)InvalidCredentialsException— неверные учетные данныеTokenExpiredException— истек срок действия токенаInvalidTokenException— некорректный формат токена
Все исключения автоматически преобразуются в соответствующие HTTP-статусы (400, 401) при использовании в FastAPI.
Пример использования
from src.auth_service import AuthService
from src.models import LoginForm, ClientLoginForm, V1RegisterRequest
# Инициализация сервиса
auth_service = AuthService(auth_config, db)
# Регистрация пользователя
register_data = V1RegisterRequest(
email="user@example.com",
password="secure_password",
full_name="Иван Иванов",
where_from="web",
why_access="work",
captcha="recaptcha_token",
client_id="client_app"
)
await auth_service.register(register_data)
# Логин пользователя
login_form = LoginForm(email="user@example.com", password="secure_password")
jwt_response = await auth_service.login(login_form)
# Логин клиентского приложения
client_form = ClientLoginForm(client_id="client_app", client_secret="secret_key")
client_token = await auth_service.login_client(client_form)
Доступ к ЛЛМ
LLM Accessor предоставляет стандартизированный интерфейс для работы с текстами, векторами, файлами и изображениями.
LLM Accessor — это универсальный шлюз для взаимодействия с современными языковыми и мультимодальными моделями (LLM и VLM). Сервис предоставляет простой и стандартизированный интерфейс для доступа к различным моделям искусственного интеллекта, позволяя разработчикам легко интегрировать мощь нейросетей в свои приложения. Благодаря гибкой архитектуре вы можете выбирать подходящие инстансы моделей, управлять запросами и получать точные ответы на текстовые и мультимодальные задачи -- всё через единый API. Это идеальное решение для тех, кто ценит время и хочет сосредоточиться на логике приложения, а не на тонкостях интеграции с разными AI-сервисами.
Сервис написан на основе библиотеки mmar-llm.
API сервиса (доступен по GRPC протоколу)
class LLMAccessorAPI:
def get_entrypoint_keys(self) -> list[str]:
raise NotImplementedError
def get_response(
self,
*,
prompt: str,
resource_id: ResourceId | None = None,
entrypoint_key: str | None = None,
max_retries: int = 1,
) -> str:
raise NotImplementedError
def get_response_by_payload(
self,
*,
payload: dict[str, Any],
resource_id: ResourceId | None = None,
entrypoint_key: str | None = None,
max_retries: int = 1,
) -> str:
raise NotImplementedError
def get_embedding(
self,
*,
prompt: str,
resource_id: ResourceId | None = None,
entrypoint_key: str | None = None,
max_retries: int = 1,
) -> list[float]:
raise NotImplementedErrorПример использования
from mmar_mapi.api import LLMAccessorAPI
from mmar_ptag import ptag_client
llm = ptag_client(LLMAccessorAPI, config.addresses.llm)
prompt: str = "Привет! Давай общаться!"
response: str = llm.get_response(prompt=prompt)Для вызова надо знать список доступных инстансов моделей. Их можно получить у сервиса:
entrypoint_keys: list[str] = llm.get_entrypoint_keys()Изменить список доступных моделей можно в конфигурации сервиса при запуске. Сервис поддерживает работу как с семействами GigaChat, YandexGPT и OpenAI, так и с моделями, доступными в OpenRouter или развернутыми локально.
Сервис быстрого извлечения текста
Text Extractor — универсальное решение для автоматического извлечения текста из документов и изображений. Поддерживает форматы PDF, JPG, PNG и другие.
Сервис Text Extractor легко интегрируется в вашу систему и позволяет быстро преобразовывать визуальную информацию в понятный LLM текстовый формат. Работает на основе Tesseract и PyPDF. Сервис гарантирует достаточную точность (CER менее 4%) и скорость обработки даже при работе с большими объемами данных.
Text Extractor отлично подходит для создания прототипов приложений в области интеллектуальной обработки документов.
API сервиса (доступен по GRPC протоколу)
class TextExtractorAPI:
def extract(self, *, resource_id: ResourceId) -> ResourceId:
"""returns file with text"""
raise NotImplementedErrorПример использования:
Для вызова надо уметь получать и отдавать файлы в систему. Это реализовано в MAESTRO с помощью абстракции FileStorage
from mmar_mapi import FileStorage
from mmar_mapi.api import ResourceId, TextExtractorAPI
from mmar_ptag import ptag_client
text_extractor = ptag_client(TextExtractorAPI, config.addresses.moderator)
file_storage = FileStorage()
resource_id: ResourceId = "data/file.pdf"
out_res_id: ResourceId = text_extractor.extract(resource_id=resource_id)
interpretation: str = file_storage.download_text(out_res_id)Модератор
FLAME — система модерации, которая анализирует выходные данные LLM для защиты от jailbreak-атак. Использует n-граммы и правила для классификации текста с высокой точностью (98.7%) и минимальными задержками (2-5 мс).
Описание
FLAME: Flexible LLM-Assisted Moderation Engine — это современное решение для эффективной и гибкой модерации контента в больших языковых моделях, также предложенное нашей командой. Традиционные системы модерации сосредоточены на фильтрации входных запросов. В отличие от них FLAME анализирует выходные данные модели, что позволяет надежнее защищаться от jailbreak-атак, включая методы типа Best-of-N. Система легко настраивается под конкретные нужды, позволяя определять запрещенные темы и оперативно обновлять правила модерации без необходимости сложного переобучения.
Принцип работы FLAME основан на использовании n-грамм и правил для классификации текста. Система преобразует сообщения в нормализованные n-граммы и сравнивает их с заранее подготовленным с помощью LLM списком запрещенных фраз. Благодаря легковесной архитектуре, FLAME требует минимальных вычислительных ресурсов — до 0.1 ядра CPU и 100 МБ оперативной памяти при работе в 1 поток. Это позволяет обрабатывать сообщения всего за 2-5 мс, обеспечивая высокую производительность даже в условиях интенсивной нагрузки.
Сервис уже успел пройти проверку на тестах и реальное внедрение в СберЗдоровье, СберМедИИ и ЦРТ Сбера. FLAME демонстрирует хорошие метрики: точность (precision) достигает 98.7%, а полнота (recall) — 90.9%. В ходе испытаний система снизила успешность jailbreak-атак в 2-9 раз по сравнению со встроенными механизмами модерации таких моделей, как GPT-4o-mini, DeepSeek-v3 и других. Низкий уровень ложных срабатываний и устойчивость к современным угрозам делают FLAME надежным решением для модерации в чат-системах и других LLM-приложениях.
API сервиса (доступен по GRPC протоколу)
class BinaryClassifiersAPI:
def get_classifiers(self) -> list[str]:
raise NotImplementedError
def evaluate(self, *, classifier: str | None = None, text: str) -> bool:
raise NotImplementedError
Детали использования
Для вызова надо выбрать классификатор. Список классификаторов можно получить от сервиса:
classifiers: list[str] = moderator.get_classifiers()На данный момент доступны классификаторы:
black— черный список (политика, религия, одиозные личности)greet— приветствияreceipt— рецептурные лекарстваchild— дети
Расширение классификаторов и создание новых
Для пополнения списков запрещённых фраз в FLAME используется специальный пайплайн генерации: с помощью немодерируемого LLM создаются многочисленные вариации сообщений по заданным запрещённым темам, которые затем разбиваются на n-граммы (до 3 слов), нормализуются и фильтруются -- в финальный чёрный список попадают только те n-граммы, которые встречаются достаточно часто и при этом не вызывают ложных срабатываний на коллекции безопасных диалогов. Тот же пайплайн можно использовать и для создания классификаторов по другим темам.
Пример использования
from mmar_mapi.api import BinaryClassifiersAPI
from mmar_ptag import ptag_client
moderator = ptag_client(BinaryClassifiersAPI, config.addresses.moderator)
text_to_check: str = "Привет!"
is_suspicious: bool = moderator.evaluate(classifier="black", text=text_to_check)
Детектор вопросов
Детектор вопросов — сервис бинарной классификации для точного определения, является ли текстовое сообщение вопросом. Использует комбинацию векторных эмбеддингов, анализ пунктуации и языковые модели для достижения точности более 99.9%.
Сервис использует комбинацию современных технологий — включая векторные эмбеддинги GigaChat, анализ пунктуации, ключевых слов и продвинутые языковые модели. Всё вместе это помогает достигать высокой точности распознавания даже в сложных и неоднозначных случаях, с которыми неизбежно сталкиваешься пока разрабатываешь автоматизацию обработки входящих запросов, чат-ботов и интеллектуальных аналитических систем.
Помимо этого, сервис легко интегрируется через удобное API, работает в реальном времени и адаптируется под различные предметные области. Для бизнес-процессов эта фича может быть крайне полезной, если вы хотите повысить их эффективность.
Сам алгоритм работает по принципу ансамблевого решения, объединяя четыре ключевых признака: семантическое векторное представление текста от GigaChat, синтаксический признак наличия вопросительного знака в конце, лингвистический признак вхождения первого слова в заранее определённый список вопросительных слов и, наконец, результат анализа большой языковой моделью по специальному промпту, который оценивает, является ли фраза вопросом, на основе контекста и смысла. Все эти признаки объединяются в единый вектор, на котором обучается бинарный классификатор, что позволяет надежно отличать вопросительные предложения от невопросительных даже в сложных случаях, когда формальные признаки противоречат семантике. Точность и полнота работы сервиса составляют более 99.9%.
API сервиса (доступен по GRPC протоколу)
class BinaryClassifiersAPI:
def get_classifiers(self) -> list[str]:
raise NotImplementedError
def evaluate(self, *, text: str) -> bool:
raise NotImplementedErrorПример вызова
from mmar_mapi.api import BinaryClassifiersAPI
from mmar_ptag import ptag_client
question_detector = ptag_client(BinaryClassifiersAPI, config.addresses.question_detector)
text_to_check: str = "Это вопрос?"
is_question: bool = question_detector.evaluate(text=text_to_check)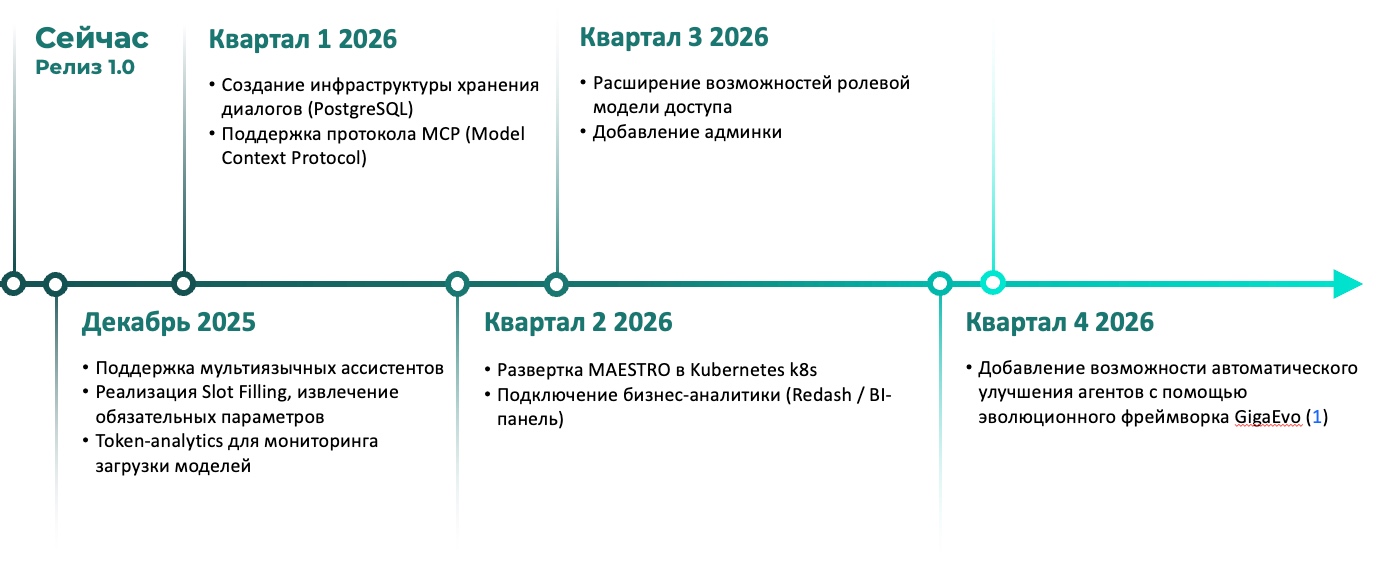
Команда

Евгений Тагин
Инженер-исследователь
AIRI

Илья Копаничук
Старший научный сотрудник
AIRI, МФТИ

Иван Бакулин
Научный сотрудник
AIRI

Владимир Шапошников
Научный сотрудник
AIRI, Skoltech

Никита Глазков
Младший научный сотрудник
AIRI, МИСИС

Игорь Трамбовецкий
Системный аналитик
AIRI

Ярослав Беспалов
Руководитель группы
AIRI